
DeepSeek-R1背后要害——多头潜在耀见地机制(MLA)迪士尼彩乐园官方,咫尺也能平缓移植到其他模子了!况兼只需原始数据的0.3%~0.6%。

在一米八海洋科技创业团队中,林峰是创始合伙人、市场发展总经理。他说,他们这个五六十人的创业团队,大部分人跨行业而来,其中不乏像他一样从大厂而来的“程序猿”,用科技赋能枸杞岛贻贝和南麂列岛大黄鱼的养殖、销售。
这项征询由复旦大学、华东师范大学、上海AI Lab等采集建议,复旦老师邱锡鹏(Moss大模子形态安祥东谈主)也在作家名单之列。

他们建议了MHA2MLA这种数据高效的微调表率,使基于MHA(多头耀见地)的谎言语模子(LLMs)粗略成功调理到MLA架构。以Llama2-7B为例,MHA2MLA在镌汰推理资本(如减少KV缓存大小92.19%)的同期迪士尼彩乐园官方,能将性能吃亏适度在较小范围(如LongBench性能仅下跌0.5%)。具体咋回事,底下咱们接着看。掌持DeepSeek中枢诀窍多头耀见地MHA(Multi-Head Attention)是Transformer架构中的一个中枢组件,允许模子同期关爱输入的不同部分,每个耀见地头皆独随即学习输入序列中的不同特征。关联词,跟着序列长度的增长,键值(Key-Value,KV)缓存的大小也会线性加多,这给模子带来了权臣的内存职守。为了管制MHA在高计较资本和KV缓存方面的局限性,DeepSeek冲突性地引入了多头潜在耀见地机制MLA。浮浅说,MLA最大调动之处在于:应用低秩采集压缩键值技能,减少了推理时的KV缓存,从而在保持性能的同期权臣镌汰内存占用。这一技能也被视为DeepSeek-V3、DeepSeek-R1等当红炸子鸡模子背后的要害。而咫尺,为了进一步镌汰其他LLMs的推理资本,征询东谈主员开采了一种能将接受MHA的模子快速适配MLA架构的表率——MHA2MLA。
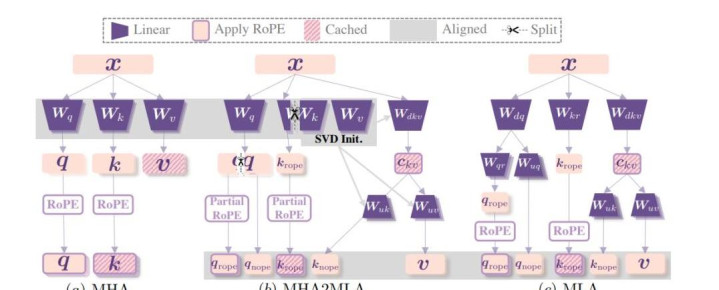
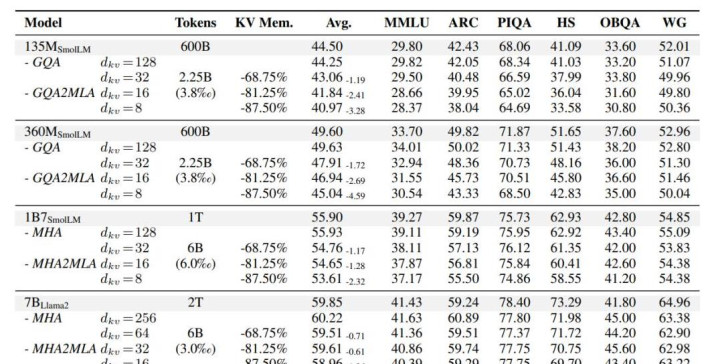
这一数据微调表率包含两个要害部分:partial-RoPE,即从对耀见地分数孝顺较小的查询和键的维度中移除旋转位置镶嵌(RoPE);低秩一样,基于预教练的键和值参数引入采集奇异值理解(SVD)一样。先说第一个。Transformer架构中,RoPE(旋转位置编码,Rotary Position Embedding) 通过旋转操作将位置信息融入查询向量Q和键向量K ,匡助模子捕捉序诸君置干系。但征询发现,在计较耀见地分数时,并非统统维度的RoPE对成果孝顺调换。换句话说,即使去除那些对耀见地分数影响较小的部分维度的RoPE,表面上不会对模子合并高下文的才调形成要害影响。基于此,征询东谈主员通过计较明锐度筹备来笃定哪些维度的RoPE孝顺较小。具体而言,关于每个维度,计较RoPE变化时耀见地分数的变化进度。一朝变化进度低于特定阈值的维度,即被判定为对耀见地分数孝顺小。在后续计较中,这些维度将不再应用RoPE。最终实考讲授,partial-RoPE这一计谋在不权臣影响模子性能的前提下,减少了计较量。再说低秩一样计谋。该表率基于预教练的键和值参数,引入采集奇异值理解(SVD)一样。SVD是一种矩阵理解技能,迪士尼彩乐园门票通过对键值矩阵进行SVD理解,不错用低秩矩阵一样原始矩阵,从而减少参数数目。具体终了中,征询东谈主员最初索取预教练模子中的键和值参数矩阵,对这些矩阵进行采集SVD理解;然后字据模子的性能和压缩需求,构建低秩一样矩阵,用这些低秩一样矩阵替代原始的键值矩阵参与后续计较。最终成果清楚,此举有用镌汰了模子推理时的计较量和内存占用。性能险些不变,将Llama2 KV缓存减少90%以上执行技艺也考证了MHA2MLA表率的有用性。能在权臣镌汰推理资本的同期,保持以致训诲模子性能。征询东谈主员选取了用MHA或GQA事前教练的不同规模(135M-7B)的LLMs,然后缔造了对照组。一组是基于传统MHA的原始模子,用于顺利对比MHA2MLA表率在调换任务和数据集上的性能进展;另一组是接受分组查询耀见地(GQA)的模子,GQA手脚MHA的变体,在一定进度上优化了计较资本,将其与MHA2MLA对比,能更赫然地展现MHA2MLA的上风。在评估其知识性推理才调的六个基准测试中,征询发现:与原始LLMs性能比较,四个基础模子的性能变化极小,135M模子性能下跌0.25%,360M、1B7和7B模子鉴别有0.03% 、0.03%和0.37%的性能训诲或保持。这标明微调数据未权臣影响原模子性能,MHA2MLA能有用终了架构迁徙,况兼微调数据仅需预教练数据的0.3%-0.6%。以致,较大模子在调理到MLA架构时性能下跌更少,这评释这一表率对规模更大的模子更有用。
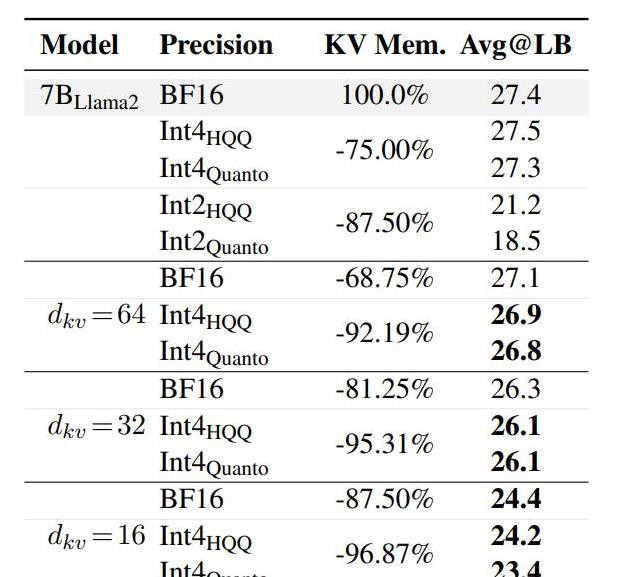
此外,在长文本生成才调评估中,以LongBench为基准,MHA2MLA比较教练后量化表率,在压缩率和精度均衡上进展出色。当dkv=16时,MHA2MLA可终了87.5%的压缩率,精度吃亏仅3%;与4-bit量化勾通明,压缩率可达92.19%(dkv=64 + Int4HQQ)和96.87%(dkv=16 + Int4HQQ),精度吃亏鉴别为-0.5%和-3.2%,优于统统2-bit量化的基线模子。这也反应了MHA2MLA表率粗略与量化技能深广兼容。
概括以上执行,不错看到以Llama2-7B为例,MHA2MLA在镌汰推理资本(如减少KV缓存大小92.19%)的同期,能将性能吃亏适度在较小范围(如LongBench性能仅下跌0.5%)。不外,论文也提到了征询局限性。受计较资源放胆,未在更大、更种种化的开源谎言语模子上考证MHA2MLA;且由于Deepseek未开源MLA的张量并行推理框架,难以探索大于7B的模子。下一步,征询东谈主员计算在更多模子上进行考证。