迪士尼彩乐园代理入口 直击黄仁勋GTC演讲: 要把“DeepSeek红利”通通吃掉
科技界泰勒·斯威夫特、Token经济学饱读励者、摩尔定律的新但愿和新晋“英伟达首席财务糟塌官”黄仁勋迪士尼彩乐园代理入口,刚刚完成了他年度最伏击演讲。
“东谈主们说我的GTC演讲就像AI界的超等碗。”黄仁勋说。“电脑行业的统统东谈主齐在这里了。”
2025年3月18日,来自全球各地的数万东谈主聚首在好意思国圣何塞,参加年度GTC大会。这场演讲委果盛况空前,圣何塞不大的市区透顶拥挤瘫痪。10点运行的演讲,有不少东谈主6点就运行列队。
这位英伟达创举东谈主兼CEO发表了长达两小时的主题演讲,扔出了一系列居品,包括BlackwellUltra版芯片,下一代芯片Rubin,要作念AI开发操作系统的Dynamo,首款电光集成交换机CPO,更苍劲的个东谈主超等电脑DGX,以及一系列机器东谈主关系的模子和平台。
这些发布,性能依旧惊东谈主。
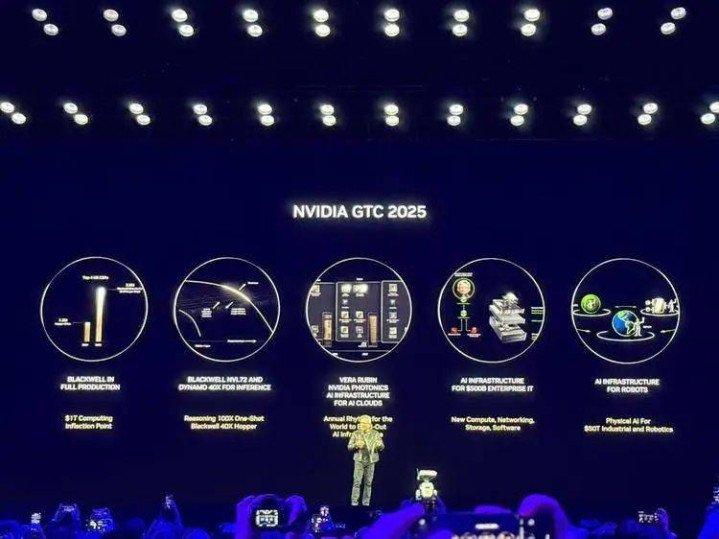
总体来看,最中枢的硬核发布包括:
1)BlackwellUltra超等芯片:专为“AI推理时间”打造,性能比上代进步1.5倍,在DeepSeekR1模子上每秒处理1000个tokens,反映时候从1.5分钟缩至10秒。黄仁勋直言“买得越多,赚得越多”。与Hopper比较,为数据中心创造50倍收入后劲。
2)VeraRubin下一代芯片:筹办2026年底推出的下一代超等芯片,内存容量是Grace的4.2倍,带宽提高2.4倍,88个CPU中枢肠能翻倍,配备288GB高带宽HBM4内存。黄仁勋还预报2027年推出VeraRubinUltra和2028年的“费曼”芯片。
3)Dynamo推理框架:黄仁勋称其为“AI工场的操作系统”,这一开源框架能和洽数千GPU通讯,通过“分离式业绩”隔离优化模子念念考和生成阶段,最大化资源诓骗率,与Perplexity达成配合开发。
4)DGX个东谈主AI超等电脑:推出MacMini大小的DGXSpark(3000好意思元)和更苍劲的DGXStation,前者提供1000万亿次/秒AI算力,128GB内存;后者搭载GB300芯片,提供20拍狡计性能和784GB内存。多家配搭伙伴将推出兼容版块。
5)IsaacGROOTN1机器东谈主基础模子:首个洞开式东谈主形机器东谈主基础模子,能不详掌持抓取、转移等复杂任务。配套推出仿真框架和蓝图器具,以及与谷歌DeepMind、迪士尼配合开发的Newton物理引擎。黄仁勋声称“通用型机器东谈主时间还是到来”。

Token经济学+AI工场:DeepSeek带来的推理红利,英伟达齐会吃掉
和过往屡次感奋东谈主心的演讲不同,本年GTC主题演讲可能是黄仁勋多年来第一次需要“回答”问题,而非统统由他设定议题的一次:
在DeepSeekR1激发的冲击后,英伟达连年来少有的被阛阓质疑:是否随着算力进入推理时间后,它代表的规模化不再成立。统统东谈主期待黄仁勋给出回答,而且就在主旨演讲前,英伟达股价运行下行,最终也以着落收盘。
这亦然聚首今日演讲的中枢。
黄仁勋的解法是:
他比统统东谈主齐愈加激进地强调推理的伏击性,何况通过下里巴人地解释以及多样英伟达真确数据和居品路子图,来证据一件事——推理时间对狡计的要求反而愈加高,辛苦经最初的英伟达会连续最初下去。
“两年前ChatGPT运行,咱们资格了多样本事的创新和跳跃,终于到了推理的时间。AI会念念考和推理,能措置更多的问题。ScalingLaw从一个造成了三个。”黄仁勋说。
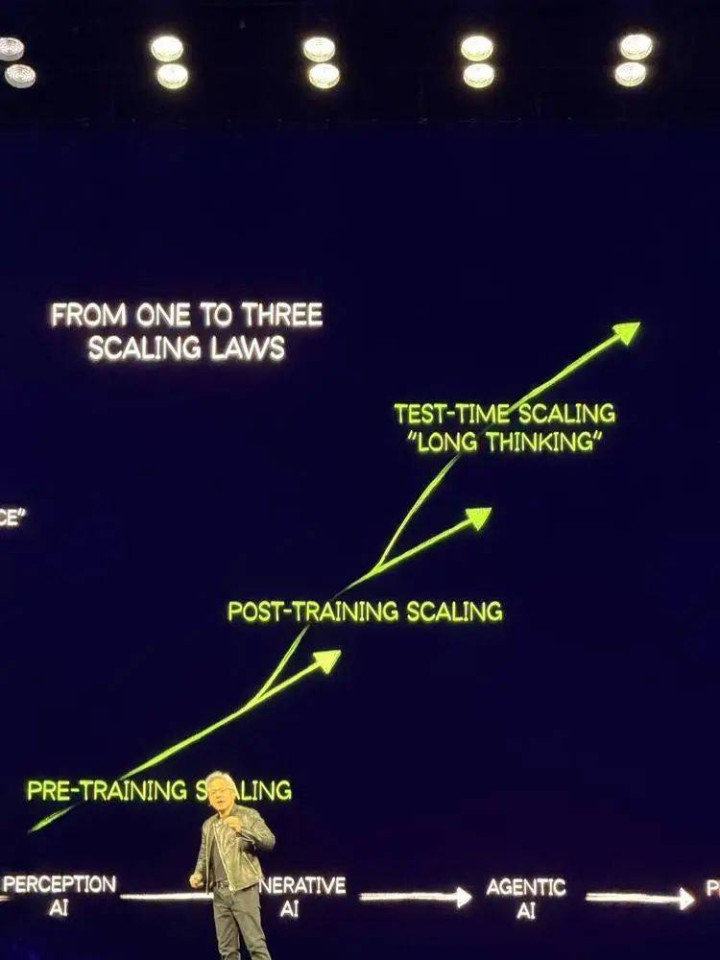
言下之意,AI向推理阶段的转动不是scalinglaw的扫尾,反而是因为Scalinglaw比东谈主们预期的发展更快,进入了这个新的阶段。
“对于扩展定律(scalinglaw)和算力,客岁全宇宙险些齐预测错了。AI的扩展定律比咱们联想的更具影响力,极大加快了狡计需求的增长。本色上,如今的算力需求比咱们客岁预估的高出了100倍。”
黄仁勋解释谈,昔时AI主要依赖训戒和预教悔数据进行学习,并能一次性完成推理演示。而现时的AI系统接收“念念维链”(ChainofThought)本事进行冉冉推理。不再仅仅精真金不怕火地预测下一个token,而是生成完好的推理程序,每个程序的输出齐会当作下一步的输入,使得处理单个查询所需的tokens数目加多了约10倍。
同期,为了保证用户体验和交互性,幸免用户因AI“念念考”时候过长而失去耐烦,系统需要以10倍的速率处理这些特等加多的tokens。因此,10倍的tokens量乘以10倍的处理速率要求,导致共狡计需求加多了约100倍。此外,教悔这些复杂推理材干需要通过强化学习处理数万亿级的tokens,进一步推高了算力需求。
“我觉得狡计有一个最终的难题,便是推理(inference)。之前统统东谈主齐以为它很精真金不怕火,但其实并不是。”黄仁勋说。
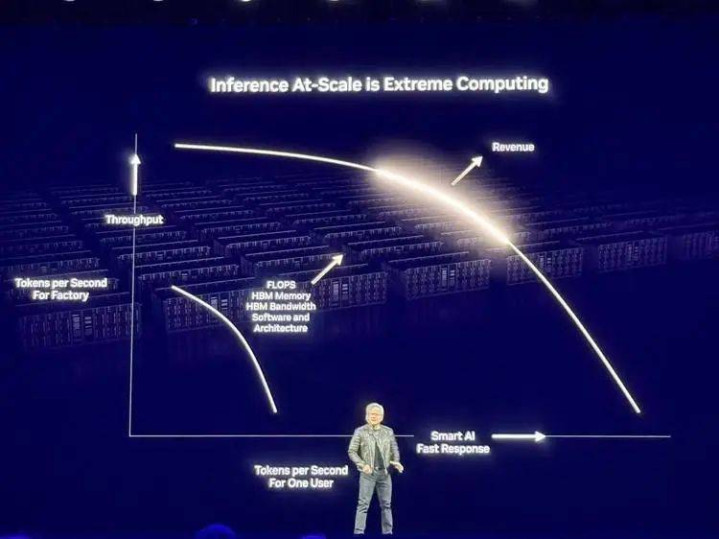
他平直把推理飞腾到了最终极挑战的地位,而这个挑战需要复杂的系统化的材干来措置,这唯独英伟达不错。
黄仁勋还用了一个demo来对比传统LLM与推理增强型模子的不同,其中推理模子他遴荐了DeepSeek。
这个例子里,两个模子要为婚宴安排座位。这直不雅展现了两者在复杂敛迹条目下(包括父母与姻亲不行相邻、影相服从最好化、新娘的特殊要求以及牧师的加入)的不同解法。
Llama3.370B接收“一次性”步地,快速生成了439个tokens的回答,固然反映赶紧但斥逐失误,等于产生了439个“浪掷的tokens”。而DeepSeekR1则启动了长远的念念考经由,生成8559个tokens,它尝试了多种可能的情境,并反复进修我方的谜底,最终得出了正确的措置决策。
从图表中不错明晰看到,比较传统LLM,推理模子的tokens生成量加多了20倍,狡计资源需求更是高出150倍。这一演示直不雅展示了当代AI为何需要更强算力——推理经由依赖多数token的处理与生成,而每生成一个token齐需要加载通盘万亿级参数的模子。“这便是为什么高速互连本事(如NVLink)变得如斯伏击——它能复古这种大规模数据转移,使AI‘念念考’成为可能。”

除了本事上的展示,他更想要的是对客户和阛阓展示信心,对此,他再次化身最强销售,他给出的谜底也不错精真金不怕火回归为一个公式:
Token经济学+AI工场=推理时间依然利好英伟达
黄仁勋从开场的视频到终末,齐在强调一件事:今天从自动驾驶,到生成式AI,一切的根源齐是token,而产生这些token的根源是英伟达。
这是黄仁勋一直在叙述的token经济学,当AI造成一切分娩力进步的根源,token就成了最压根的单元。若何让每个生成的token齐合算,便是今天统统企业要温暖的事情。
今天,电脑的地位透顶发生蜕变,以往它是软件索取信息的地点,现时它是产生Token的地点,它是AI工场。而当作一个工场,就要狡计干预产出比。黄仁勋把AI输出的token觉得是老本,而每个用户大致赢得的token则是收益。
纵轴是当作AI工场的输出,计量单元是每兆瓦生成的TPS(每秒touken数),横轴是用户得到的TPS。一个弧线能在横轴和纵轴齐推广,你的收入就越多。
而横轴更高的同期纵轴越低的话,你就能越赢利。
而英伟达的居品,在连接激动着这个赢利弧线的扫尾。
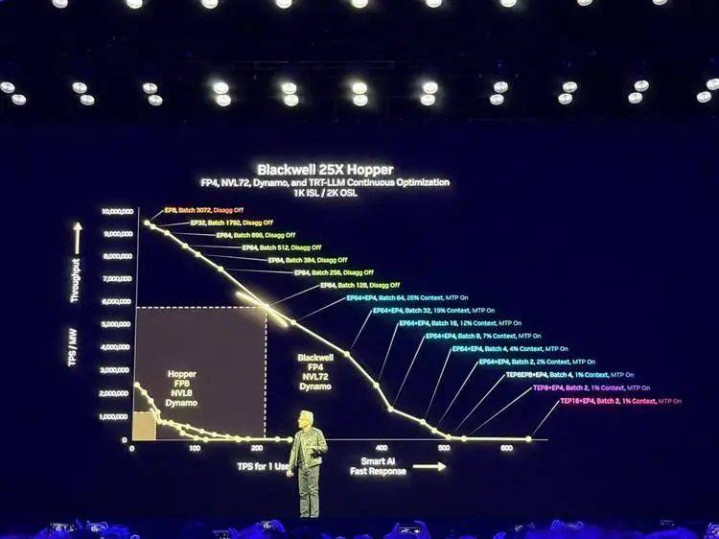
黄仁勋在图里平直对比了Blackwell与Hopper:一个1兆瓦的Hopper数据中心每秒可产生约250万tokens,而接收一样功耗的Blackwell系统(结合NVLink72、FP4精度和Dynamo系统),性能可进步25倍。特别是在推理模子上,Blackwell的推崇更为出色,性能比Hopper高出40倍。
“当Blackwell运行多数出货时,你基本上送给别东谈主Hopper齐不会要。”他笑着说:“别怕,Hopper在某些情况下如故不错的……这是我能对Hopper说的最好的话了。”
这样说昭彰对Hooper这个还在销售的居品线是稠密打击,他开打趣说,我方造成了“首席财务糟塌官”。
在比较100兆瓦AI工场时,黄仁勋指出,基于Hopper的工场需要45,000个芯片和1,400个机架,每秒产生3亿tokens,而Blackwell则需要更少的硬件扫尾更高的性能。固然Blackwell单价可能更高,迪士尼彩乐园专注彩票但其狡计服从的进步使AI工场在恒久运营中从简更多老本。
“基本上你买得越多,省得越多!不,以致比这更好——买得越多,赚得越多!”这句经典的黄仁勋数学,再次用在了推理时间。
这一切齐利好英伟达,AI的投资会连续,行将达到万亿好意思元的拐点。
“我之前说过,预测到2028年,数据中心的竖立将达到万亿好意思元规模,而我特别服气咱们很快就会达到这个筹办。”
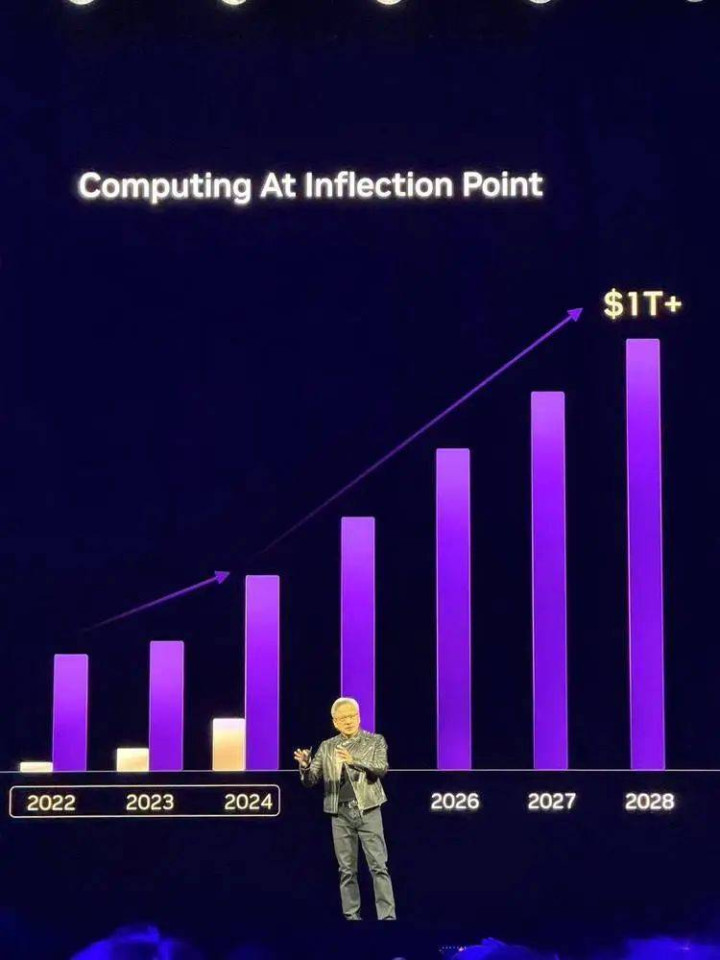
阛阓的高预期下,把货“卖”到了2027年
具体来看这次黄仁勋带来的新址品的最新细节。
NVIDIABlackwellUltra:
它是NVIDIABlackwell新一代版块——NVIDIABlackwellUltra。BlackwellUltra专为“AI推理时间”遐想,这类本事随着DeepSeekR1的推出而进入主流。
BlackwellUltra基于客岁推出的Blackwell架构打造,包括两大中枢居品:GB300NVL72机架式系统和HGXB300NVL16系统。GB300NVL72的AI性能比上一代进步了1.5倍,而与使用Hopper架构的数据中心比较,收入后劲提高了50倍。
黄仁勋示意:“AI还是扫尾了稠密飞跃:能进行推理和自主活动的AI需要成倍增长的狡计性能。咱们专为这一时刻遐想了BlackwellUltra,这是一个多功能平台,不错不详高效地完成预教悔、后教悔和AI推理。”

GB300NVL72在一个机架式遐想中联接了72个BlackwellUltraGPU和36个基于Arm架构的GraceCPU。有了这个系统,AI模子不错诓骗更苍劲的狡计材干探索不同的问题措置决策,将复杂央求领会为多个程序,从而提供质料更高的回答。
凭据英伟达的说法,GB300NVL72系统在运行DeepSeek的R1东谈主工智能模子时,每秒能处理1000个tokens,而使用老款Hopper芯良晌只可每秒处理100个。这一升级意味着本色使用中,GB300NVL72只需约10秒就能回答用户问题,而Hopper则需要1.5分钟材干完成同样的任务。精真金不怕火来说,新一代BlackwellUltra系统比旧款Hopper系统快了近9倍,是一次质的飞跃。
这款居品也将在英伟达的DGXCloud平台上提供,这是一个端到端的全托管AI平台,通过软件、业绩和专科学问优化性能。而使用GB300NVL72遐想的DGXSuperPOD系统则为客户提供了一站式的“AI工场”。
HGXB300NVL16系统在处理大型语言模子时速率比上一代快11倍,狡计材干提高7倍,内存容量增大4倍,足以移交最复杂的AI任务,如高等推理。
Blackwell芯片现时已全面投产,据称,这是英伟达历史上最快的产能进步。在最近一个季度中,Blackwell为英伟达孝顺了110亿好意思元收入,占公司总收入393亿好意思元的近三分之一。
下一代AI“超等芯片”VeraRubin:
舍弃本年1月的2025财年,英伟达销售额扫尾了惊东谈主的翻倍增长,达到1246.2亿好意思元。这主要归功于两方面:Hopper芯片的持续热销和Blackwell芯片的早期订单。
要保持这样的增长势头,英伟达必须推出让客户“钱花得值”的新一代芯片。这意味着新芯片需要在速率更快、耗电更少、总领有老本更低等方面卓绝上一代居品。

黄仁勋初次展示了下一代VeraRubinAI超等芯片,这款居品以以暗物资商议前驱天文体家VeraRubin定名,预测将于2026年底推出。这款芯片延续了前代居品的遐想理念,接收CPU(Vera)和GPU(Rubin)组合架构。
主要升级包括:内存容量是Grace的4.2倍,内存带宽提高2.4倍,88个CPU中枢提供比GraceBlackwell两倍的全体性能,以及RubinGPU中的288GB高带宽内存4(HBM4)。
还有一个多月就马上过年了,每年的除夕,央视春晚可以说是当天的重头戏,每年也在各地增设不同的分会场,为了的就是迎合不同地方老百姓的口味,可谓真的是下足的功夫啊。其实每个地方的人都希望能够在春晚上看到自己地方的特色,但我们这个地方真的是太大,好的东西太多,估计选也选不过来啊。
“基本上统统东西齐是全新的,除了机箱,”黄仁勋说谈。
黄仁勋还预报了2027年的后续居品:VeraRubinUltra,这款居品将接收RubinUltraGPU,将四个GPU合并为一个单元。
阛阓的预期之高,英伟达需要把2027年的货提前走漏给环球看。
黄仁勋示意,AI正处于“拐点”,预测到2028年数据中心收入将达到1万亿好意思元。英伟达代号为“费曼”(Feynman)的下一代AI芯片将于2028年亮相。
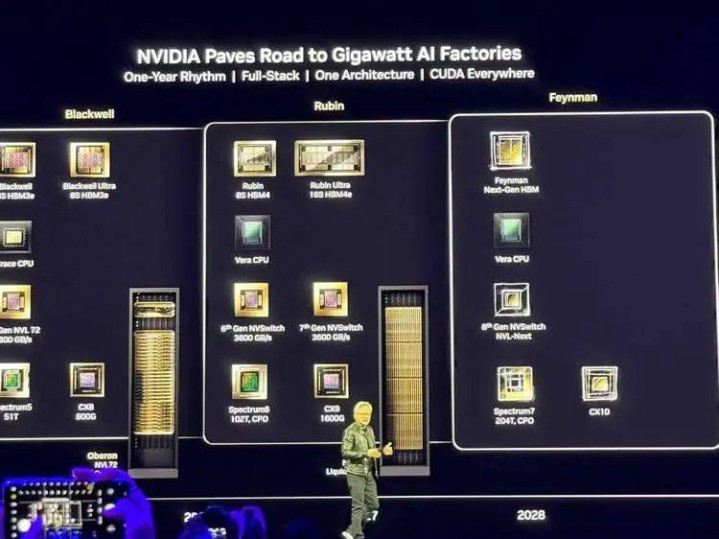
NvidiaDynamo:AI工场的操作系统
黄仁勋发布了开源推理框架Dynamo,用于加快和扩展AI推理模子。黄仁勋称之为“AI工场的操作系统”,并解释说这个名字着手于工业革掷中的第一个重要发明—发电机(Dynamo)。
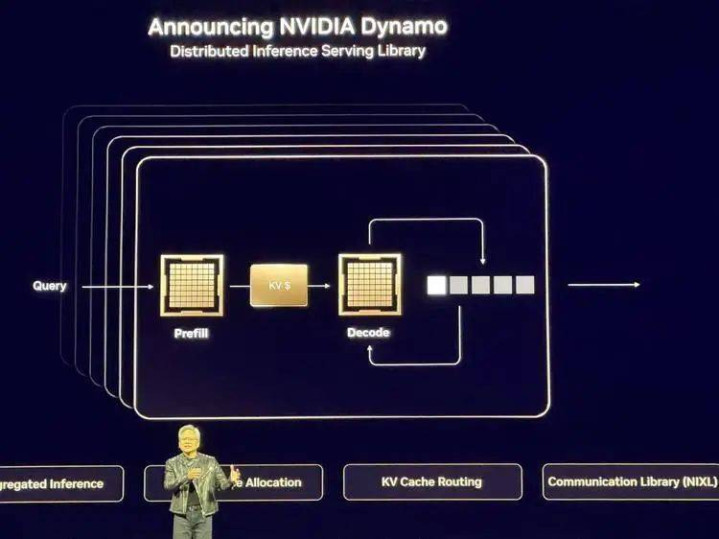
Dynamo专为部署推理型模子的“AI工场”遐想,匡助最大化产出效益。它能和洽停加快洪水横流GPU之间的通讯,并接收“分离式业绩”本事,在不同GPU上分开处理大语言模子的“念念考阶段”和“生成阶段”。这样每个阶段齐能针对特定需求进行独处优化,确保GPU资源得到最充分诓骗。
黄仁勋走漏,英伟达正在与“最可爱的配搭伙伴”之一Perplexity配合开发Dynamo。“特别可爱他们,不仅因为他们作念的立异性责任,还因为Aravind是个很棒的东谈主”
DGXSpark、DGXStation:家用“AI超等电脑”
黄仁勋还带来了面向个东谈主用户的“AI超等电脑”——DGXSpark和DGXStation。两款开导齐接收了GraceBlackwell平台,为用户提供腹地运行大型AI模子的材干,而无需持续联接数据中心。其中较小的Spark版块现已洞开预订。
DGXSpark是英伟达本年在CES展会上以“Digits”为名发布的那款MacMini大小的“宇宙最小AI超等电脑”,售价3000好意思元。而更大的DGXStation则面向“AI开发者、商议东谈主员、数据科学家和学生,用于在桌面上原型遐想、微赞成运行大型模子”,现时尚未公布价钱。

Spark搭载了英伟达的GB10Blackwell超等芯片,配备第五代Tensor中枢和FP4复古。提供“高达1000万亿次每秒(TOPS)的AI狡计材干,足以微赞成运行最新的AI推理模子,包括英伟达CosmosReason宇宙基础模子和NVIDIAGROOTN1机器东谈主基础模子”。Spark配备128GB归拢内存和最高4TB的NVMeSSD存储。
体积更大的DGXStation容纳了英伟达刚刚发布的更苍劲的GB300BlackwellUltra桌面超等芯片,“提供20拍(petaflops)的AI性能和784GB归拢系统内存”。
英伟达还文书OEM配搭伙伴将推出我方版块的DGX开导:华硕、戴尔、惠普、Boxx、Lambda和超微将打造我方的DGXStation,将于本年晚些时候上市。华硕、戴尔、惠普和期许将推出DGXSpark版块
英伟达并非独一打造具有大归拢内存、可用于腹地大语言模子的GPU厂商。AMD也推出了RyzenAIMax+“StrixHalo”芯片。这些开导的出现,意味着苍劲的AI狡计材干正从云表走向家庭和个东谈主,为肤浅用户提供了腹地AI运算材干。
黄仁勋还文书了对其汇注组件的更新,以便将数百或数千个GPU联接在沿路,使它们当作一个全体协同责任同期,英伟达在汇注本事方面也取得了进展,推出了基于光子学的Spectrum-X和Quantum-X交换机,进步了数据中心GPU互联的服从和可扩展性。

小机器东谈主Newton:
此外还有英伟达与谷歌DeepMind和迪士尼商议院配合,专为开发机器东谈主而遐想Newton开源物理引擎。
在先容NVIDIA与DeepMind、Disney和NVIDIA联合研发的机器东谈主Newton时,演示视频忽然中断。闇练GTC节拍的东谈主齐知谈,那味儿又来了。
“若何回事,咱们只剩两分钟了,我需要跟真东谈主言语。”黄仁勋故作焦急地往复漫步,“什么,正在再行退换架构,那是什么酷好....”话音刚落,Newton机器东谈主Blue就从舞台一侧渐渐起飞。随后一边发出电影里那样古灵精怪的机械声,一边沾沾自喜地走到了黄仁勋身边,全场爆发出掌声与笑声。

“告诉我这是不是很惊东谈主!嘿Blue,你可爱你的新物理引擎吗?触觉反馈、刚体和软体模拟,及时物理狡计。我敢打赌你可爱!”黄仁勋特别指出,现场不雅众看到的一切齐是及时模拟,这将是畴昔机器东谈主教悔的重要步地,并走漏Blue里面搭载了两台NVIDIA狡计机。
而Blue也与黄仁勋互动,随着作念出点头、扭捏的回话,并听从他的交流站到驾御。这亦然整场发布和演讲中,艰巨的不详时刻。

今天是个猖獗的时间,英伟达不错把芯片的架构更新提高到一年一次,但即便如斯,东谈主们的胃口似乎依然莫得得到知足。
黄仁勋似乎也对此有些不爽,在演讲里,他稍许吐槽谈:
“咱们发布了新东西,但东谈主们立时会说好的,接下来呢?这对任何公司齐不正常。”他说。
“毕竟这不像买个札记本电脑,咱们需要有筹办,地盘迪士尼彩乐园代理入口,动力,咱们的东谈主的部署,这齐需要提前几年作念筹办。是以咱们可能不行让你很吃惊,但一切齐在按照筹办进行。”